
Escrevi esse artigo com o propósito de poder ajudar a esclarecer alguns conceitos básicos quando se trata da utilização de índices nos bancos de dados. Já vi e ouvi muita gente que pensa que a utilização de índices é a solução geral para problemas de performance nas consultas, e o contrário também, que índices são coisas de outro mundo e que atrapalham o desempenho.
O banco de dados de uma aplicação é um grande fator que influencia a sua performance. Uma aplicação que tenha seu código escrito utilizando as melhores práticas, melhores componentes, otimizado ao máximo, não será eficiente se sua base de dados não puder ser performática também, e isso pode causar uma falsa impressão de que a aplicação está mal feita.
O uso de índices no banco de dados pode ser um fator decisivo entre melhorar a performance ou piorá-la. Para saber o porquê dessa importante posição que ocupa os índices, é preciso entender o que são e como um banco de dados os trata.
Um índice é uma estrutura distinta no banco de dados. Ele requer seu próprio espaço em disco e contém uma cópia indexada do dado da tabela. Isso significa que o índice é pura redundância. Criar um índice não altera os dados da tabela, ele apenas cria uma nova estrutura que refere-se a tabela. Um índice de banco de dados é muito parecido como o índice de um livro: ele ocupa seu próprio espaço, é altamente redundante, e refere-se a informação atualmente contida em um lugar diferente. (Referência 1)
Espaço ocupado pelos dados e pelos índices das tabelas do banco de dados mysql
Então a criação sem controle de índices pode facilmente começar a ocupar o espaço livre em disco desnecessariamente. Essa criação descontrolada prejudica também a performance das operações DML (insert, update, delete), pois a cada operação realizada, é necessário que o índice seja manipulado também.
Para utilizar de uma melhor forma os índices, deve-se levar em consideração alguns fatores. Um desses fatores a se pensar antes de criar um índice é se realmente ele é necessário. Existe um conceito chamado de “seletividade” que deve ser levado em conta quando pensar se realmente é necessário o índice.
Quando um índice é criado, gera um arquivo no disco como já foi visto, e quando o banco de dados gera o plano de execução para a query que utiliza o índice, ele analisa se o trabalho necessário para buscar no arquivo do índice, e depois os valores relacionados na tabela, é maior que o trabalho de pesquisar diretamente na tabela. É nesse momento que a seletividade faz sentido, pois um índice que retorna uma grande quantidade de dados não deve ser tão performático quando fazer a pesquisa na própria tabela. Então quanto menor é a seletividade do índice, quanto mais registros ele traz para um determinado filtro, menor é a necessidade desse índice. (Referência 2)
Outro fator, quando se cria índices compostos, aqueles com mais de uma coluna, é a ordem em que as colunas são colocadas na hora de criar. Essa ordem é tão importante na criação do índice quanto na sua utilização dentro da cláusula where. Como exemplo, podemos pensar em uma lista telefônica ordenada por nome e sobrenome. Utilizando os dois registros em ordem, a busca é simples, mas quando se usa fora de ordem ou somente um dos campos para fazer a busca, fica muito mais complexo encontrar o registro do que somente percorrer a lista.

Criação de uma tabela para teste com índices compostos (MySQL)
Ao criar esse índice composto, também é necessário avaliar se a primeira coluna usada para esse índice já não é a chave primária da tabela. Esse cuidado é importante pois isso pode tornar o índice inútil. Quando é criado o plano de execução para uma busca, se o índice primário é encontrado em primeiro lugar, o plano assume que a melhor maneira de executar é justamente a utilização dessa chave primária, ignorando esse índice composto. Isso acontece pois para um índice composto, é levado em conta primeiro a coluna mais à esquerda do índice (a primeira coluna descrita na criação). Se somente a coluna (ou as colunas) após a primeira for utilizada, o plano de execução não considera o índice para utilização. (Referência 3)
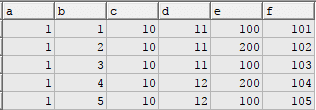
Tabela teste com alguns dados
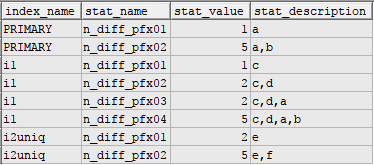
Tabela com os índices criados e a quantidade de registros para cada agrupamento dos índices compostos. Repare que não há registro de índice começando pela segunda coluna de um índice composto. (O MySQL incrementa os índices não únicos com a chave primária, como é no caso do índice i1)
Esses pontos apresentados são apenas orientações básicas. A criação de índices é uma operação que envolve algumas coisas mais complexas, como a quantidade de leitura de blocos dos arquivos gerados, variações do tipo de índice criado, índices parciais e outros. Ter em mente esses simples pontos, pode fazer a diferença entre poder dizer que um índice está sendo a solução para um problema ou sua causa.
Referências
-
Anatomy of an SQL Index – http://use-the-index-luke.com/sql/anatomy
-
Slow Indexes, Part II – http://use-the-index-luke.com/sql/where-clause/the-equals-operator/slow-indexes-part-ii
-
Concatenated Indexes – http://use-the-index-luke.com/sql/where-clause/the-equals-operator/concatenated-keys
-
Chapter 14 The InnoDB Storage Engine – http://imysql.com/mysql-refman/5.7/innodb-storage-engine.html
